文字報導
Sora 2引發著作權爭議 台灣出版業防線薄弱




【記者丘旻軒報導】集英社、角川等17日本家出版社和協會於10月31日發表聯合聲明,指出影像生成式AI 「Sora 2」(註1)不僅未經授權使用他人創作進行資料訓練,且採取「選擇退出」 (註2)模式,有違日本著作權規範。此外,集英社也強調,政府應明確制定機器學習和著作權之間的界限與規範。相較之下,由於台灣目前尚未出現重大侵權案例,因此社會對此議題的關注度仍相對不足。出版業資深編輯Z(化名)指出,生成式AI已成為著作權領域的重要議題,政府應加速建立完善的資安與資料管理機制,以因應生成式AI所帶來的智慧財產權風險。
註1:Sora 2是OpenA於民國114年推出的最新AI影片生成模型,也是首個支援「畫面與聲音同步生成」的版本,可用簡單的文字説明生成短片。
註2:選擇退出(Opt-out)模式是指除非權利人明確申請排除旗下版權物,否則該版權物將會被主動用於AI生成與學習。
 聯合聲明指出,AI進行機器學習的過程需遵守三項標準,包含使用的資料須經授權、訓練過程需公開、給予版權方合理的補償機制。圖/截自公益社團法人日本漫畫家協會
聯合聲明指出,AI進行機器學習的過程需遵守三項標準,包含使用的資料須經授權、訓練過程需公開、給予版權方合理的補償機制。圖/截自公益社團法人日本漫畫家協會
由於生成式AI基礎模型仰賴大量資料進行訓練,因此實務上即便資料受版權保護,仍可能被納入訓練使用。以Sora 2為例,該AI推出不久後,社群上便出現大量與《海賊王》、《火影忍者》等知名動畫IP極為相似的內容。然而,這並非首宗生成式AI侵權爭議的案例。早在112年,紐約時報就指控Open AI無償利用旗下大量新聞進行深度學習,並產出相同風格的作品。
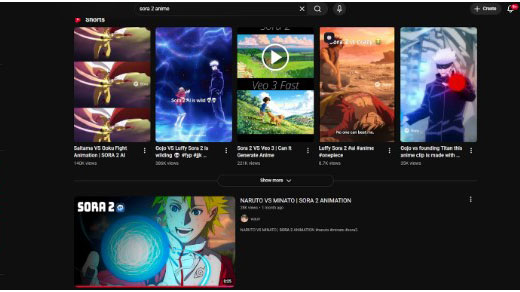 若在YouTube搜尋「Sora 2 anime」或「Ai anime」等關鍵字,即會找到多部與日本著名動畫風格幾乎一致的短片。圖/截取自YouTube
若在YouTube搜尋「Sora 2 anime」或「Ai anime」等關鍵字,即會找到多部與日本著名動畫風格幾乎一致的短片。圖/截取自YouTube
然而,全球各地如今正陷入AI與版權方的法律攻防戰,台灣卻尚未針對人工智慧生成設立母法,缺乏AI資料授權與生成規範的具體規定,只能以現行的《著作權法》等法規來處理爭議。安倍晉三研究中心資深研究員戴凡芹認為,政府推動《人工智慧基本法》的積極程度,反映一國看待AI侵權的態度,「著作權是創作者的心血,未經同意使用資料明顯屬於侵權。」他也補充,雖然台灣整體立法步調偏慢,但日本經濟產業省與法制局因應人工智慧產業的措施可以作為借鏡。
 行政院於8月28日通過《人工智慧基本法》草案,並已送交立法院審議。學者戴凡芹指出,草案第九條與第十條對利益衝突與責任歸屬提出規範,但相關內容仍有待進一步討論與釐清。圖/擷取自行政院全球資訊網
行政院於8月28日通過《人工智慧基本法》草案,並已送交立法院審議。學者戴凡芹指出,草案第九條與第十條對利益衝突與責任歸屬提出規範,但相關內容仍有待進一步討論與釐清。圖/擷取自行政院全球資訊網
除了法律制度外,知識產業界對於如何因應生成式AI仍未形成一致共識。Z指出,出版界普遍缺乏危機意識,「許多出版社不是認為自身不會受到影響,就是對侵權問題的嚴重性認識不足。」目前AI資料庫多以公開資訊為主,並可自由檢索,但由於出版社普遍欠缺技術、人力與資金支援,往往錯失防範侵權的最佳時機。此外,盜版網站更成為AI爬蟲資料庫的漏洞,使大量內容遭到擅自抓取與學習。中時新聞網副總編輯戴志揚也表示,媒體目前難以有效阻止AI爬蟲抓取資料,即便要舉證生成式AI涉及違法重製,仍受制於技術不足的困境。不過,他也強調,若涉及重大獨家新聞,媒體將會嚴正以待,採取必要的維權行動。
要求授權,是出版社基本的權益保障。戴凡芹認為,即使短時間難達成授權協議,至少也要提供版權方權利救濟的機制,例如創作者發現IP被未經授權的單位使用,可以請對方立刻下架或賠償。同時,他也建議中小型知識產業與出版商透過保留創作過程、申請專利與特殊商標等方式以便舉證侵權。Z則認為,依資料使用量分配收益非必要,反而可以由AI公司出資建立「AI賦能出版基金」,以提升出版社數位化與AI應用的能力,降低生成式AI對知識產業界的衝擊。
 台南應用科技大學漫畫系老師陳漢玲表示,雖然「創作風格」難以從版權角度明確界定,但仍可依作品數量作為評估金額的依據。圖/丘旻軒攝
台南應用科技大學漫畫系老師陳漢玲表示,雖然「創作風格」難以從版權角度明確界定,但仍可依作品數量作為評估金額的依據。圖/丘旻軒攝
